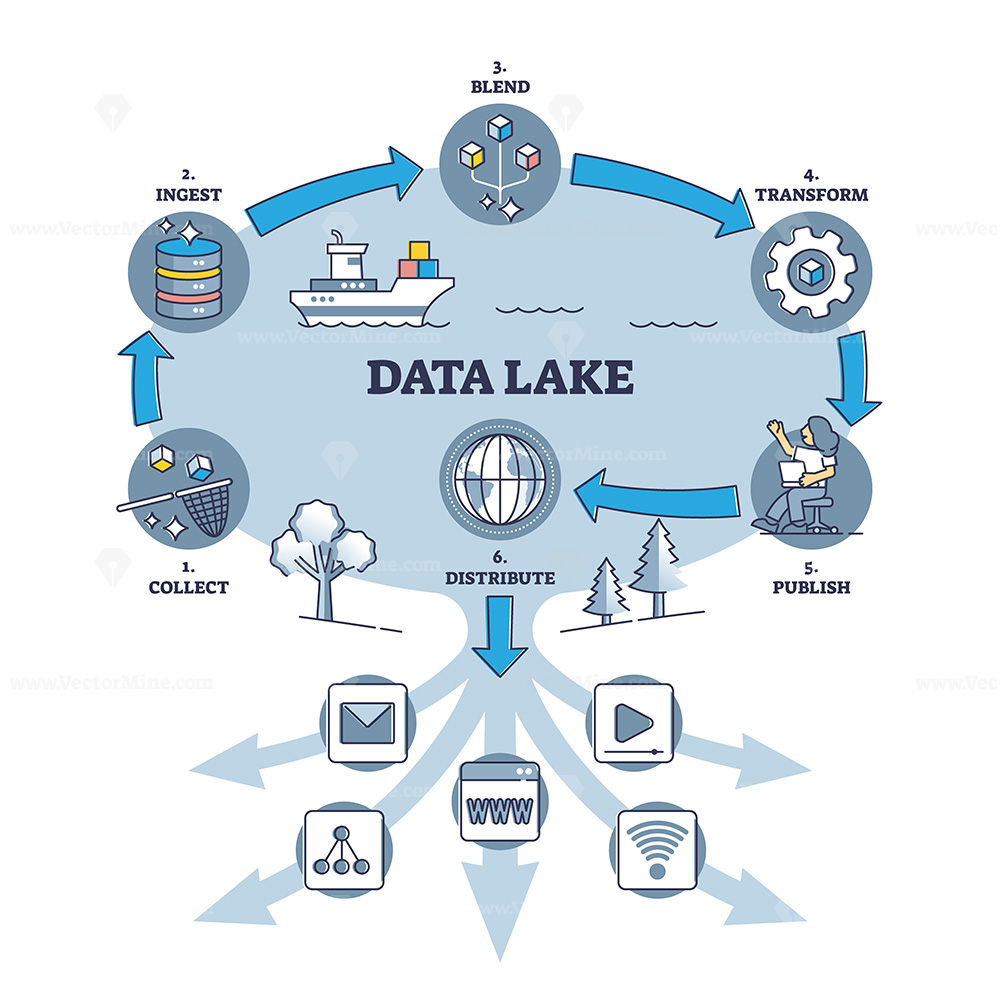
Delta Lake is an open-source storage layer that can be used to build a data lake. Here is an example of how you can use Delta Lake to build a data lake:
- Start a Spark cluster: To use Delta Lake, you will need to start a Spark cluster. You can do this by downloading the latest version of Spark from the Apache website and following the instructions to install it on your system.
- Create a Delta Lake table: In order to store data in a Delta Lake table, you will need to create a new table. You can do this by using the Spark SQL API, for example:
from delta.tables import *
deltaTable = DeltaTable.create(spark, "path/to/data", "id INT, name STRING")- Load data into the table: After creating the table, you can load data into it. This can be done using the Spark Dataframe API, for example:
data = spark.read.format("csv").options(header="true", inferSchema="true").load("path/to/data.csv")
data.write.format("delta").mode("overwrite").save("path/to/data")- Perform data operations: With data loaded into the table, you can perform data operations such as filtering, aggregation, and join.
data_filtered = spark.read.format("delta").load("path/to/data").filter("id > 5")
data_aggregated = spark.read.format("delta").load("path/to/data").groupBy("id").agg({"name":"count"})- Optimize performance: Delta lake provides a feature called “Optimized table” that allows the user to optimize the performance of the table. This can be done using the command line tool “delta”, for example:
delta optimize path/to/data- Monitor and maintain: Finally, it is important to monitor the performance of the Delta Lake data lake and make sure that it is running smoothly. This can be done using the Delta Lake’s built-in web UI and various monitoring tool like Grafana.
